Final Report: Stream processing support for FasTensor
Final Report: Stream processing support for FasTensor
Project Description
FasTensor is a scientific computing library specialized in performing computations over dense matrices that exhibit spatial locality, a characteristic often found in physical phenomena data. Our GSoC'24 project aimed to enhance FasTensor by enabling it to ingest and process live data streams from sensors and scientific equipment.
What is FasTensor?
Imagine you’re working on a physical simulation or solving partial differential equations (PDEs). You’ve discretized your PDE, but now you face a new challenge: you need to run your computations fast and parallelize them across massive compute clusters.
At this point, you find yourself describing a stencil [1] operation. But should you really spend your time tinkering with loop orders, data layouts, and countless other side-quests unrelated to your core problem?
This is where FasTensor comes in: Describe your computation as a stencil, and it takes care of ensuring optimal execution. FasTensor lets you focus on the science, not the implementation details.
Repository Links
- FasTensor: https://github.com/BinDong314/FasTensor
- My fork: https://github.com/my-name/FasTensor/tree/ftstream
PR(s)
Work done this summer
Develop Streaming simulator: FTStream
I was first entasked by Dr. Bin to develop a stream simulator for testing the streaming capability of FasTensor. For testing purposes, a stream is characterized by file size, count, and arrival interval. FTStream can generate streams of various sizes and intervals, up to the theoretical limits of disk and filesystem. We’re talking speeds up to 2.5 GiB/s on a non-parallel NVMe!
Writing this tool was an adventure in throughput testing and exploring APIs. I wrote multiple drivers, each for a different whim and hijinks of systems in the HPC world. Here’s a brief journey through the APIs we explored:
HDF5 APIs: Pretty fast in flush-to-disk operation, but the API design strongly binds to file handles, which inhibits high throughput duplication.
HDF5 VFL and VOL: We dabbled in these dark arts, but there be dragons! Keeping a long-term view of maintenance, we dropped the idea.
POSIX O_DIRECT: This involved getting your buffers aligned right and handling remainders correctly. A step up, but not quite at the theoretical limits.
Linux AIO: Streaming is latency sensitive domain, to reach the theoretical limits, every syscall saved matters. Linux AIO allowed us syscall batching with
io_submit(). It took a few testing sessions to get the correct combo of queue depth, buffer size, and alignment right.
We settled on O_DIRECT + Linux AIO. Feel free to modify ftstream/fastflush.h to suit your needs.
Stream Support
FasTensor has just one simple paradigm: you give it a data source, an output data store, and your transform, and it handles all the behind-the-scenes grunt work of computing over big datasets so you can focus on your research.
We aimed to achieve the same for streaming: Drop in the STREAM keyword, append a pattern identifying your stream, and use your usual transform.
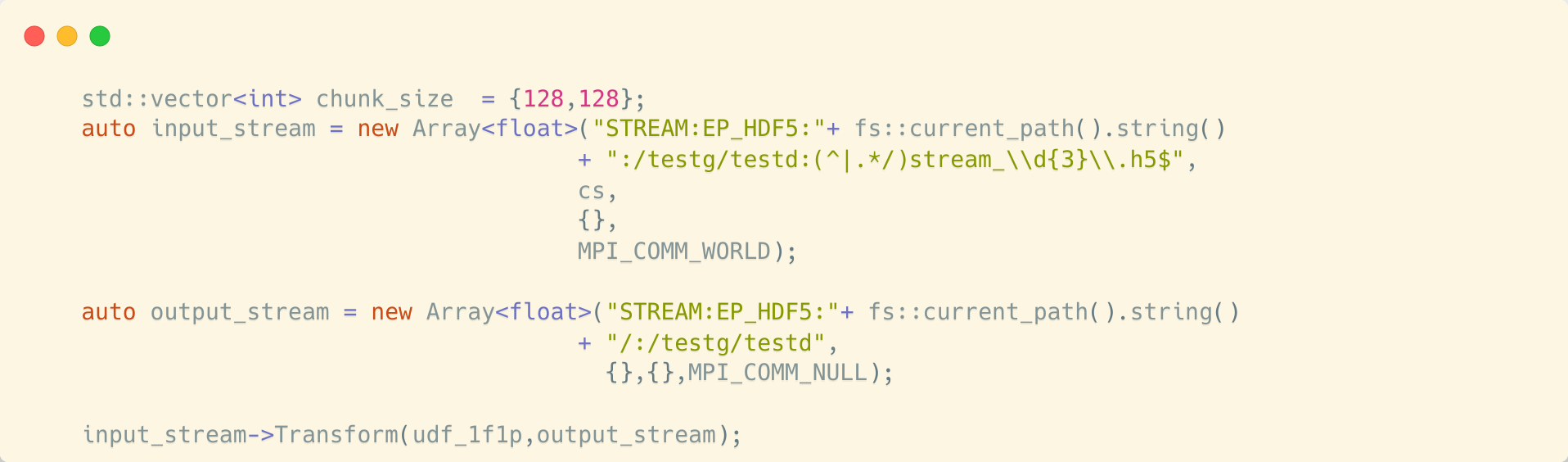 Voila! Now your previous FasTensor code supports live data streams.
Voila! Now your previous FasTensor code supports live data streams.
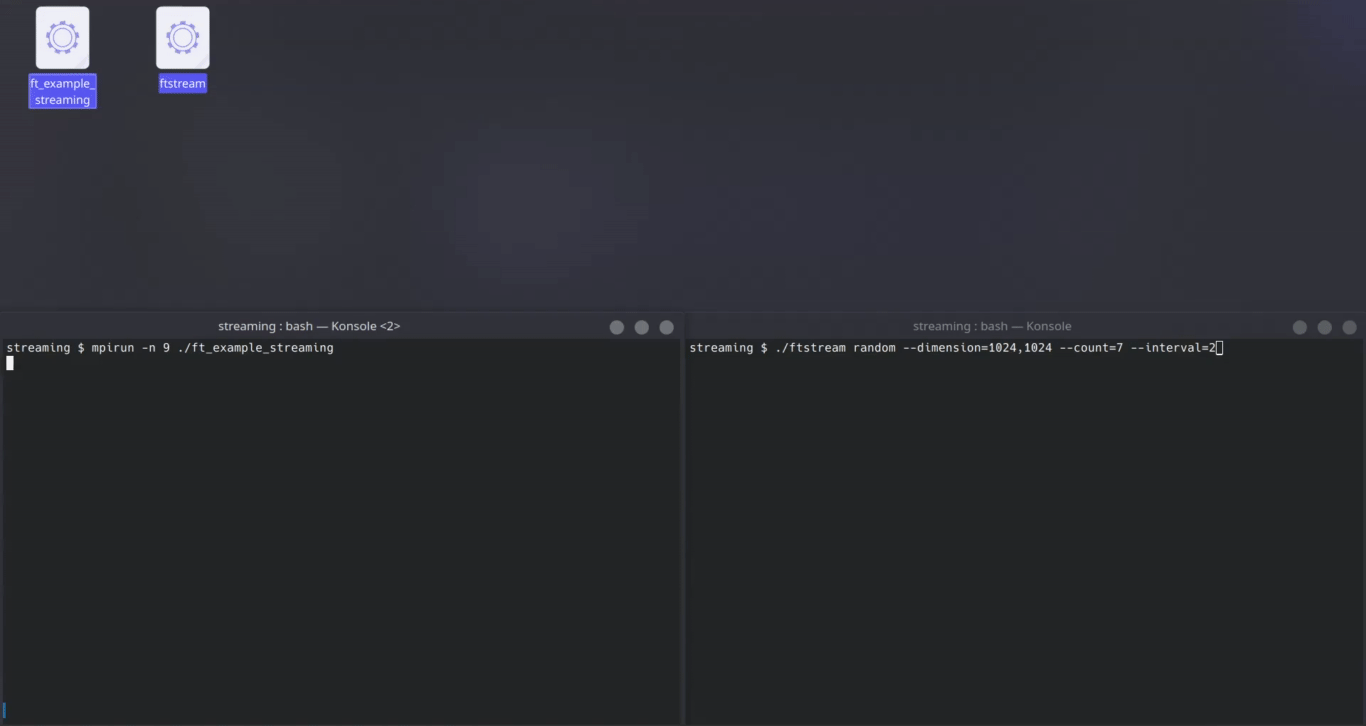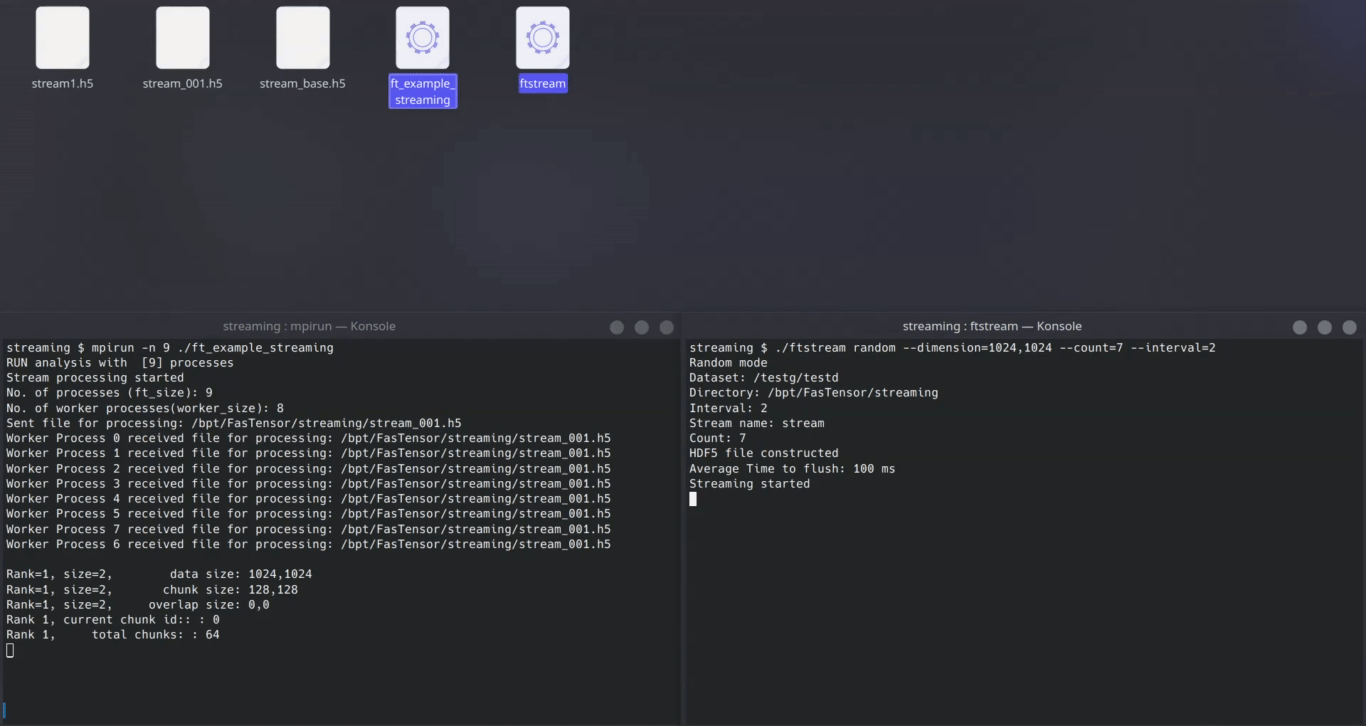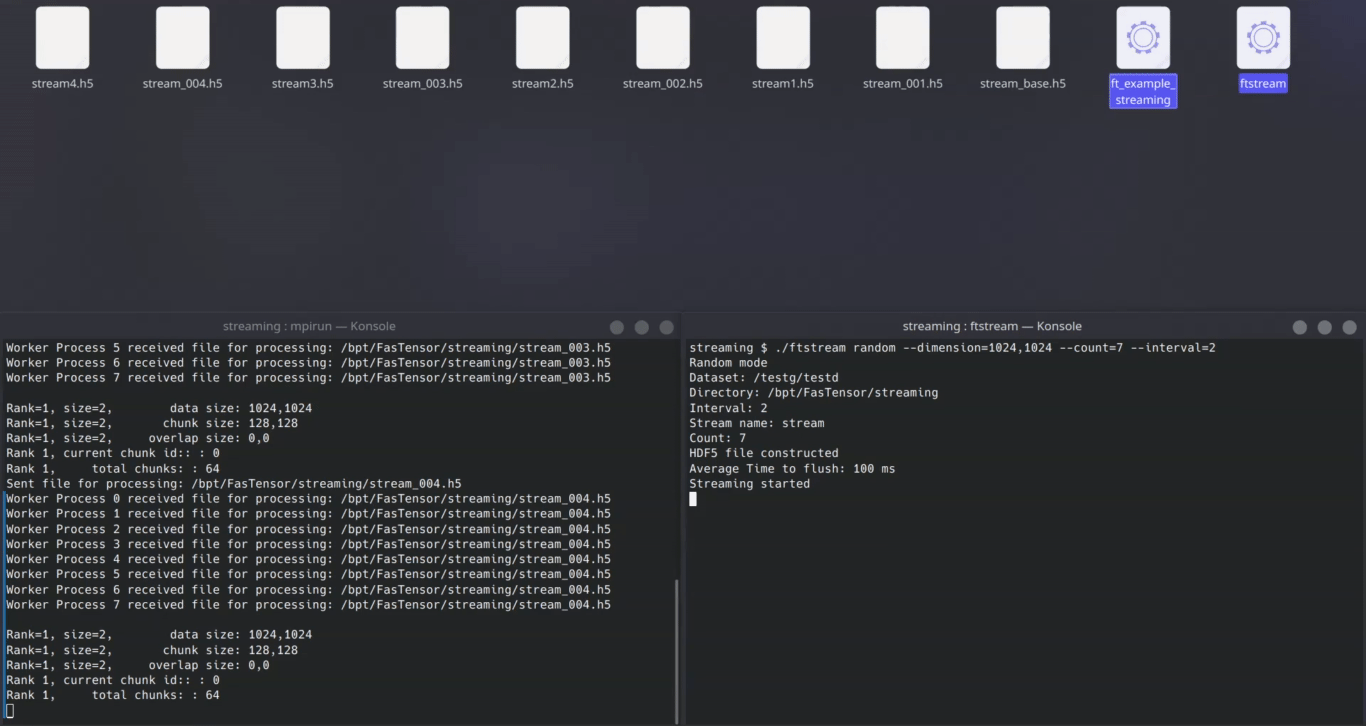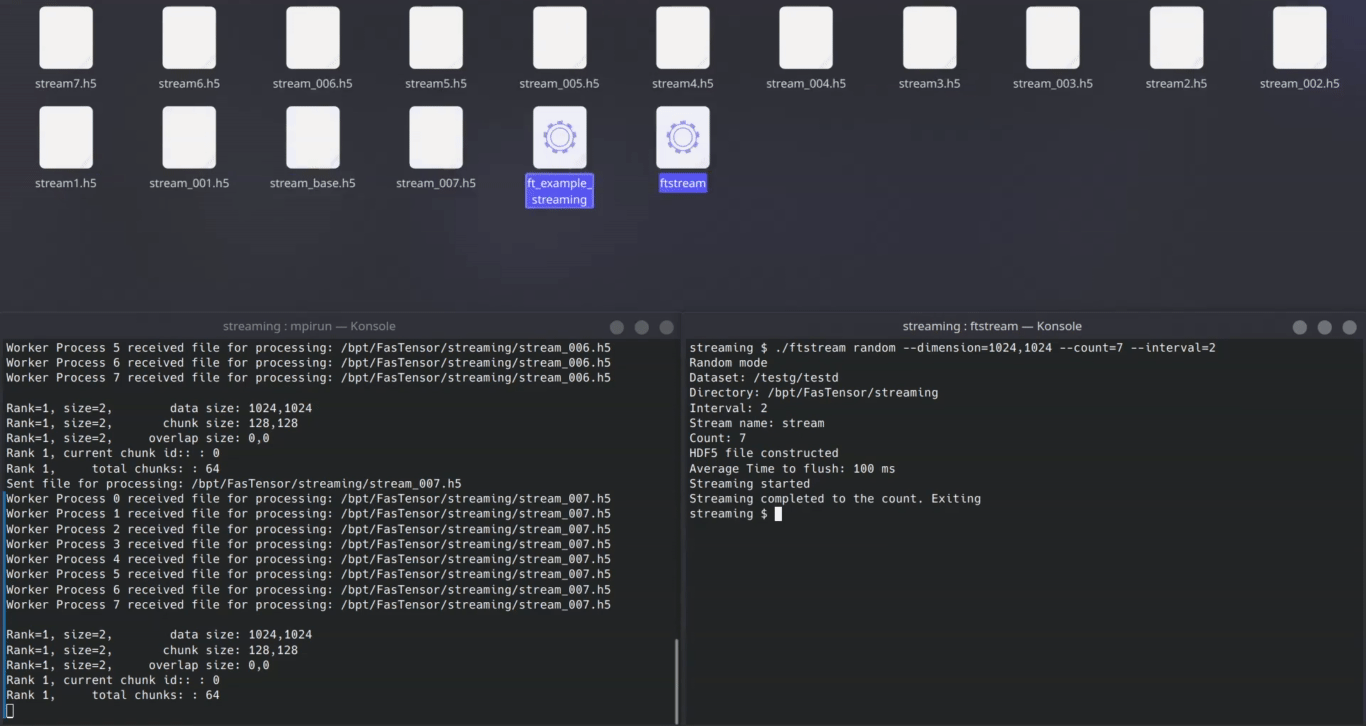
Technical tidbits:
- Implements a manager-worker pattern to allow us flexibility in the future to implement different stream semantics such as windowing, CPU-memory based load balancing
- Supports streams of indefinite size
Challenges
HPC has its fair share of challenges. Things you take for granted might not be available there, and it takes a while to adjust to paradigms of scale and parallelization.
For example, when developing FTStream, we found O_DIRECT is available on some parallel file systems like GPFS but not supported on Lustre/CFS. We developed a separate MPIO driver for FTStream that will be upstreamed once thoroughly tested on Lustre.
Future Work
- Implement windowing and explore more advanced stream semantics.
- Implement support for for defining workload policies
- Optimize interleaving IO and Compute.
References
[1] Anshu Dubey. 2014. Stencils in Scientific Computations. In Proceedings of the Second Workshop on Optimizing Stencil Computations (WOSC ‘14). Association for Computing Machinery, New York, NY, USA, 57. https://doi.org/10.1145/2686745.2686756
Acknowledgement
I struck gold when it comes to mentors.
Dr. Bin Dong was really kind and supportive throughout the journey. From the very first steps of giving a tour around the codebase to giving me a lot of freedom to experiment, refactor, and refine.
Dr. John Wu was encouraging and nurturing of budding talent. We had great research presentations every Monday apart from usual mentor interactions, where different research groups presented their talks and students were invited to present their progress.
I’ve come across Quantum computing many times in the news, but I never thought I’d get a frontline preview from the researchers working at the bleeding edge at the Lawrence Berkeley National Laboratory (LBL).
This GSoC experience, made possible by Google and UC OSPO, has been invaluable for my growth as a developer and researcher.
For people interested in HPC, ML, Systems, or Reproducibility, I encourage you all to apply to UC OSPO. It’s been an incredible journey, and I’m grateful for every moment of it!
Aditya Narayan
CS Undergraduate, Amity Noida
I am passionate about crafting high-performance production systems and making computing a delightful and user-centric experience.
Bin Dong
Research Scientist, Lawrence Berkeley National Laboratory
Bin’s research interests are in high-performance computing + big data + AI/non-AI.
John Wu
Senior Computer Scientist, Lawrence Berkeley National Laboratory
John is a Senior Computer Scientist at Lawrence Berkeley National Laboratory. He works on data management, data analysis, and scientific computing. His algorithmic research work includes feature extraction, indexing techniques, tensor data processing, and scientific computing.